
Here's how OpenAI Token count is computed in Tiktokenizer - Part 2
In this arcticle, we will review how OpenAI Token count is computed in Tiktokenizer. We will look at:
-
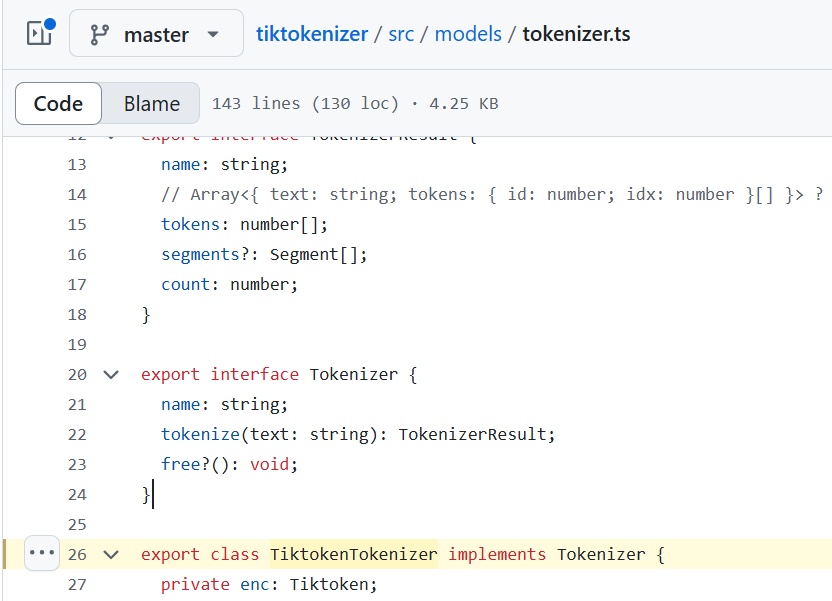
Tokenizer interface
-
TiktokenTokenizer
For more context, read the part 1.
Tokenizer interface
In tiktokenizer/src/models/tokenizer.ts, at line 20, you will find the following code
export interface Tokenizer { name: string; tokenize(text: string): TokenizerResult; free?(): void; }
This interface is implemented by a class named Tiktokentokenizer as shown below
export class TiktokenTokenizer implements Tokenizer {
TiktokenTokenizer
You will find the following code at line 26 in tiktokenizer/src/models/tokenizer.ts.
export class TiktokenTokenizer implements Tokenizer { private enc: Tiktoken; name: string; constructor(model: z.infer<typeof oaiModels> | z.infer<typeof oaiEncodings>) { const isModel = oaiModels.safeParse(model); const isEncoding = oaiEncodings.safeParse(model); console.log(isModel.success, isEncoding.success, model) if (isModel.success) { if ( model === "text-embedding-3-small" || model === "text-embedding-3-large" ) { throw new Error("Model may be too new"); } const enc = model === "gpt-3.5-turbo" || model === "gpt-4" || model === "gpt-4-32k" ? get_encoding("cl100k_base", { "<|im_start|>": 100264, "<|im_end|>": 100265, "<|im_sep|>": 100266, }) : model === "gpt-4o" ? get_encoding("o200k_base", { "<|im_start|>": 200264, "<|im_end|>": 200265, "<|im_sep|>": 200266, }) : // @ts-expect-error r50k broken? encoding_for_model(model); this.name = enc.name ?? model; this.enc = enc; } else if (isEncoding.success) { this.enc = get_encoding(isEncoding.data); this.name = isEncoding.data; } else { throw new Error("Invalid model or encoding"); } } tokenize(text: string): TokenizerResult { const tokens = [...(this.enc?.encode(text, "all") ?? [])]; return { name: this.name, tokens, segments: getTiktokenSegments(this.enc, text), count: tokens.length, }; } free(): void { this.enc.free(); } }
constructor
This below code is picked from the TiktokenTokenizer class.
constructor(model: z.infer<typeof oaiModels> | z.infer<typeof oaiEncodings>) { const isModel = oaiModels.safeParse(model); const isEncoding = oaiEncodings.safeParse(model); console.log(isModel.success, isEncoding.success, model) if (isModel.success) { if ( model === "text-embedding-3-small" || model === "text-embedding-3-large" ) { throw new Error("Model may be too new"); } const enc = model === "gpt-3.5-turbo" || model === "gpt-4" || model === "gpt-4-32k" ? get_encoding("cl100k_base", { "<|im_start|>": 100264, "<|im_end|>": 100265, "<|im_sep|>": 100266, }) : model === "gpt-4o" ? get_encoding("o200k_base", { "<|im_start|>": 200264, "<|im_end|>": 200265, "<|im_sep|>": 200266, }) : // @ts-expect-error r50k broken? encoding_for_model(model); this.name = enc.name ?? model; this.enc = enc; } else if (isEncoding.success) { this.enc = get_encoding(isEncoding.data); this.name = isEncoding.data; } else { throw new Error("Invalid model or encoding"); } }
This constructor is used to set this.name and this.enc.
At line 42, you will find the following code
const enc = model === "gpt-3.5-turbo" || model === "gpt-4" || model === "gpt-4-32k" ? get_encoding("cl100k_base", { "<|im_start|>": 100264, "<|im_end|>": 100265, "<|im_sep|>": 100266, }) : model === "gpt-4o" ? get_encoding("o200k_base", { "<|im_start|>": 200264, "<|im_end|>": 200265, "<|im_sep|>": 200266, }) : // @ts-expect-error r50k broken? encoding_for_model(model);
get_encoding returns a value that is assigned to enc.
get_encoding is imported as shown below:
import { get_encoding, encoding_for_model, type Tiktoken } from "tiktoken";
Tiktoken is fast BPE tokenizer for use with openAI models.
Learn more about tiktoken
tokenize
In the same class, tokenize is defined as following:
tokenize(text: string): TokenizerResult { const tokens = [...(this.enc?.encode(text, "all") ?? [])]; return { name: this.name, tokens, segments: getTiktokenSegments(this.enc, text), count: tokens.length, }; }
This returns an object that contains name, token, count and segments.
This is the function that is used in tiktokenizer/src/pages/index.tsx at line 48.
const tokens = tokenizer.data?.tokenize(inputText);
free
free has the following code
free(): void { this.enc.free(); }
About me:
Hey, my name is Ramu Narasinga. Email: ramu.narasinga@gmail.com
Tired of AI-generated code that works but nobody understands?
I spent 3+ years studying OSS codebases and wrote 350+ articles on what makes them production-grade. I built an open source tool that reviews your PR against your existing codebase patterns.
Your codebase. Your patterns. Enforced.